
Elasticsearch is a beginner’s game
introduce
The first time in nuggets published articles, some inadequacies, do not beg spray! Please don’t spray! Please don’t spray! As a front-end, ES was actually implemented because of the use of the full stack project of wiki documents in our company. Due to the increasing number of articles and the demand for full-text search, and the original mongodb database was very slow in full-text search, es was introduced. Vehicle 300 tool platform, the project is not yet public, is expected to be released in 2021.
The origin of Lucene
Doug Cutting, an American engineer who became fascinated with search engines, built a library of functions (software functional components) for text search called Lucene. Lucene was written in JAVA with the goal of adding full-text retrieval capabilities to a variety of small and medium sized applications. It is popular with programmers because it is easy to use and open source. It was initially maintained by the man himself, and later expanded to become a subproject of the Apache Software Foundation Jakarta project in late 2001.
Lucene is an information retrieval kit, JAR package, does not contain the search engine system! Index structure, tools for reading and writing indexes, sorting, search rules… Utility class!
Lucene and Elasticsearch
ElasticSearch is based on Lucene with some encapsulation and enhancements. Es is an open source, highly scalable, distributed, full text search engine. It was born in the era of big data in the 21st century. Restful apis. In 2016, it surpassed Solr to become the no. 1 search engine app.
Elasticsearch history
Years ago, Shay Banon, an unemployed developer who was recently married, went with his wife to London to study cooking. While he was looking for a job, he started using the Lucene toolkit to build a recipe search engine for her. Since using the native toolkit directly was a hassle, he began abstracting Lucene code to write his own package, which he later rewrote when he got a job and named ElasticSearch. Then, in February 2010, the first public version of ES was released, which quickly became one of the most popular projects on Github. A company focused on ES was formed, which developed new features and made them commercially available, and was open source forever. Unfortunately, Shay’s wife is still waiting for recipe search….
What is a search?
1) Baidu, Google. We can search for what we need by entering some keywords. 2) Internet search: e-commerce websites. Recruitment website. News website. Various apps (Baidu takeout, Meituan, etc.) 3) Search on Windows system, etc
Bottom line: Search is everywhere. Through some keywords, give us query out the information related to these keywords
What is full text search?
Full-text retrieval refers to the computer indexing program through scanning every word in the article, to establish an index for each word, indicating the number and position of the word in the article, when the user queries, the retrieval program will be based on the index established in advance to search, and the search results feedback to the user retrieval method. This process is similar to looking up words through the search word table in a dictionary.
What is Elasticsearch?
Java language development of a set of open source full-text search engine for search, log management, security analysis, index analysis, business analysis, application performance monitoring and other fields based on Lucene open source library development, providing restAPI, can be called by any language support distributed deployment, Scalable, updated, iterative, community active, well documented (this article was 7.9.1 in September 2020 and now 7.10.x in November)
Go to the official website to download Win Linux and other versions of the installation package
Link: ElasticSearch download
Git Clone ik word Splitter is a Github project, available with git Clone or zip download
Kibana download
For the sake of demonstration, here is a tutorial for Windows, how to distribute Linux online and so on.
Familiar with ES directory

Options Java VM configuration file -- ElasticSearch. Yml ElasticSearch configuration file (default)9200Port! Lib related JAR package logs log modules Related module plugins such as IKCopy the codeStart the
Direct access to thebindirectoryelasticsearch.bat

Install the visualization plugin ElasticSearch -head
git clone https://github.com/mobz/elasticsearch-head.git
Copy the codeOnce in the directory
cnpm install
Copy the codeAccess localhost:9100 to find a cross-domain problem
Go to the es config directory for elasticSearch.yml to add cross-domain configuration
http.cors.enabled: true
http.cors.allow-origin: "*"
Copy the code* indicates that all users can access it. The actual formal environment cannot be configured in this way
Restart ElasticSearch and then go to localhost:9100

Installation and use of Kibana
Understand the ELK
ELK is short for Elasticsearch, Logstash, and Kibana open source libraries. ELK is also called Elastic Stack. Elasticsearch is a near real-time search platform framework based on Lucene, distributed and Restful interaction. Scenarios of big data full-text search engines such as Baidu and Google can use ES as the underlying support framework. It can be seen that ES provides powerful search capabilities. Logstash is the central data flow engine, which is used to collect data in different formats from different targets (files/data storage /MQ). After filtering, output is only supported to different destinations (file /MQ/redis/ ES, etc.). Kibana is an ES visualization tool that provides real-time analysis capabilities.
Collect cleaning data –> search, save –>Kibana

Make sure the Kibana version is consistent with es
Kibana Windows download address, click to download
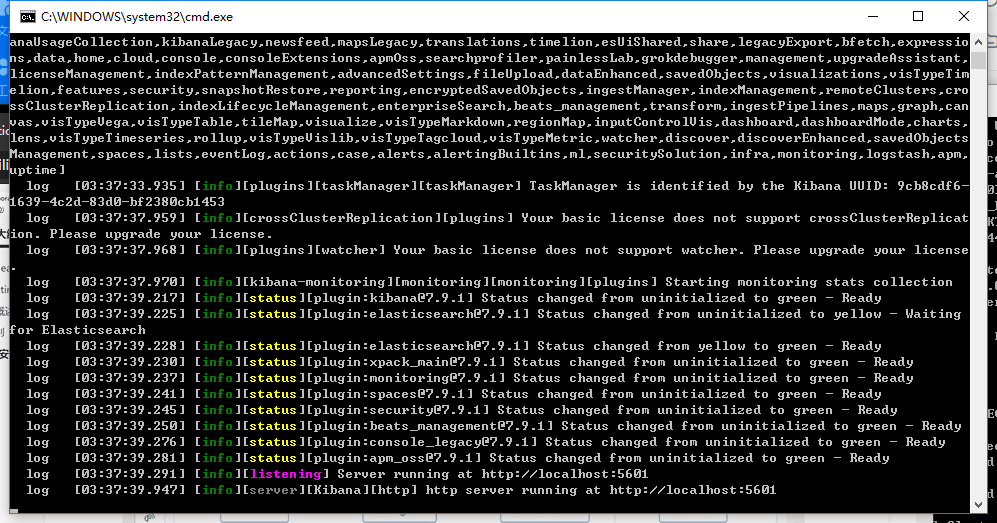
Start the
Bat in the kibana-7.9.1-windows-x86_64\bin directory
| 
|_
Copy the codeAccess port 5601
Ps: Development tools! (Postman, etc.)
Modify the localization
Go to configuration file D:\tools\ Kibana-7.9.1-windows-x86_64 \config\kibana.yml
i18n.locale: "zh-CN"
Copy the codeEs Core Concepts
Es is a document-oriented non-relational database
| Relational database | es |
|---|---|
| The database | The index |
| table | Types (slowly deprecated, 7.x.x uses uniform _doc and can be omitted in query commands) |
| line | Documents (documents) |
| field | fields |
The document
Es is document-oriented,
- This means that the smallest unit of index and search data is a document, similar to a row in a table in a relational database.
- Documents are serialized to JSON format, and JSON objects consist of fields (stored in JSON format)
- Each field has a corresponding field type, which can be specified or automatically calculated using ElasticSearch (smart).
- JSON documents support arrays and nesting (high degree of freedom)
- Each document has a unique ID, which can be specified by itself or automatically generated by the system (intelligent)
Although we are free to ignore a new field, but the type of each field is very important, such as an older type fields, can be a string can also be a integer, because es are saved in the mapping between fields and types, and other Settings, this mapping specific to each type of each map, which is why in es, Types are sometimes called mapping types.
The main elements of a document generally contain the following:
_type: name of the type to which the document belongs (discarded) 3. _ID: unique ID of the document 4. _source: Json data stored in the document 5. Relevance scoreCopy the codetype
Types are logical containers for documents, and just like a relational database, tables are containers for rows.
The index
The most direct understanding is the database!
- Each index is a very large collection of documents.
- Each index has its own Mapping that defines the field names and field types of the document
- Each index has its own Settings that define different data distributions, i.e. indexes that use sharding (I haven’t used
 )
)
How do nodes and clusters work
A cluster has at least one node, and a node is an ES process. A node can have multiple indexes (default). If you create an index, there will be 5 primary shards in the index, and each primary shard will have a replica.

Since I’m not a professional at this, I’ve passed over these things here… You don’t need to know too much about the bottom
What is an inverted index
Es uses a structure called an inverted index, with the Lucene inverted index as the underlying structure. This structure is suitable for fast full-text indexing. An index consists of all the non-repeating lists in a document, and for each word, there is a list of documents containing it. For example, there are now two documents, each containing the following:
To forever, Study every Day, good good up, to forever # document1Copy the codeTo create an inverted index, we split each document into separate terms (terms), then create a sorted list of all non-repeating terms, and then list which documents each term appears in

Now we’re going to search for “To Forever” by looking at the document that contains each term

This is where the weights come in!
Conclusion: Inverted index helps us completely filter out some useless data, which helps us improve efficiency
1, index (database) 2, field type (mapping) 3, document 4, Fragment (Lucene index)
Word splitter (IK word splitter)
Word segmentation is to divide a Duan Zhongwen or English for each keyword, we will put their information when the search for word segmentation, the database or index to participle in the library data, and then do a matching operation, the default of Chinese word segmentation is to each word as a word, such as “I love education instrument” will be divided into “I” love “” “instrument “, “education” This is obviously not reasonable, so we need to install Chinese word segmentation. IK provides two word segmentation algorithms: IK_smart and IK_MAX_word, where IK_SMART is the least sharded and IK_max_word is the most fine-grained!
Install IK word segmentation package 1, install 2, directly decompress to es installation directory plugin directory named IK 3, restart ES
Verify whether the word segmentation is installed, 4, useelasticsearch-plugin

5. Test with Kibana!
Ik_smart has the least partition



Ik_max_word is divided at most


The best practices for both types of segmentation are ik_max_word for indexing and IK_smart for searching. That is: index to maximize the content of the word segmentation, search more accurate search to the desired results.
1, ik_max_word
The text will be the most fine-grained split, such as the “People’s Republic of China great Hall of the People” split into “People’s Republic of China, People’s Republic of China, China, Chinese, People’s Republic, People’s Republic, great Hall, general assembly, hall and other words.
2. Ik_smart will split “The Great Hall of the People of the People’s Republic of China” into “the Great Hall of the People of the People’s Republic of China”.
Found the problem


This kind of word we need, we need to add our word participle, will realize the real word segmentation
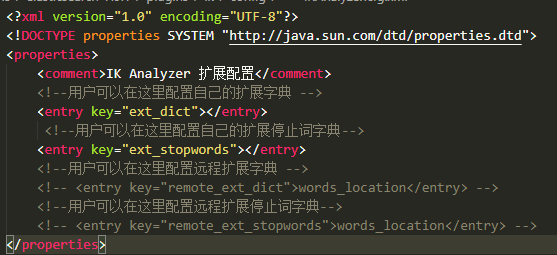
Add your own dictionary
D: tools\ ElasticSearch -7.9.1\plugins\ik\config\ ikAnalyzer.cfg. XML (this is my path, others are different from me) modify in this directory
| 
|_
Copy the codeinElasticsearch - 7.9.1 \ plugins \ ik \ configCreate a user-defined dictionary in the directory. For example: 1yuyi.dic2. Write to the file

GET _analyze {"analyze ": "ik_smart", "text": "analyze "}Copy the codeThe return value has changed
{" tokens ": [{" token" : "super", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0}, {" token ":" like ", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1}, {" token ": "Training instrument", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 2}, {" token ":" speak ", "start_offset" : 6, "end_offset" : 7, "type" : "CN_CHAR", "position" : 3 } ] }Copy the codeLater, you need to configure yourself, you need to set in the participle
Rest Style Description
This is an architectural style rather than a standard, and it is used for client-server interaction classes, so software can be designed in this style with more simplicity, hierarchy, etc.
| method | The url address | describe |
|---|---|---|
| PUT | Localhost :9200/ index name/type name/document ID | Create document (specify document ID) |
| POST | Localhost :9200/ Index name/type name | Create document (random document ID) |
| POST | Localhost :9200/ Index name /_update/ document ID | Modify the document |
| DELETE | Localhost :9200/ index name/type name/document ID | Delete the document |
| GET | Localhost :9200/ index name/type name/document ID | Query documents by document ID |
| POST | Localhost :9200/ index name/type name /_search | Query all data |
Create a document
Example 1
PUT /test1/type1/1
{
"name":"Training instrument"."age":24
}
Copy the codeType names will be removed in future version 8

Example 2
PUT /test3/_doc/1
{
"name":"Parenting Sharing Session"."age":24."birth":"1996-09-12"
}
Copy the codeHere _doc is the official type of es in the future. In the future, the type name will be removed and _doc will be unified as a system
If we do not specify a document type, ES will specify the type for us by default

Field specified type
- The value can be text or keyword
- Value types: Long, INTEGER, short, byte, double, float, half float, scaled Float
- Date type: date
- Te Boolean type: Boolean
- Binary type: binary
- And so on…
test
PUT /test2
{
"mappings": {
"properties": {
"name": {"type": "text"
},
"age": {"type": "long"
},
"birthday": {"type": "date"}}}}Copy the code
Mappings and properties are mandatory formats for the specified field types, and name, age, and birthday are the types that users want.
Get information through a GET request
GET /test2
Copy the codeYou can retrieve all of the test2 index information directly with a GET request

Extension: Use the command to view the ES index
View the database health value
GET _cat/health
Copy the code
Check es for a lot of information
GET _cat/indices? vCopy the code
And so on and so forth
Modify the
Modify the commit or use PUT and override! (The old way)
PUT /test3/_doc/1
{
"name":"Sharing session 20200921"."age":24."birth":"1996-09-12"
}
Copy the code
Updated approach (new)
POST /test3/_update/1
{
"doc": {"name":"The Demon King of Yoyi."}}Copy the code
nameThe field has changed. It’s worth notingdocIt’s a fixed notation
delete
Drop the entire index
DELETE /test1
Copy the codeThe return value:

Delete a piece of data
Delete /test3/_doc/1
Copy the codeUsing RESTFUL style is recommended by ES!
Operations on documents
Basic operation
1. Create an index and add data
PUT /yuyi/_doc/1
{
"name":"Zhu Yuyi"."age":24."desc":"I'm sharing it tomorrow. My panicked batch."."tags": ["Geek"."Warm"."Straight"]
}
PUT /yuyi/_doc/2
{
"name":"Zhang"."age":24."desc":"I'm Joe."."tags": ["Silly fork." "."Travel"."Men who cheat on women's affections."]
}
PUT /yuyi/_doc/3
{
"name":"Bill"."age":30."desc":"I'm Li Si."."tags": ["Pretty girl"."Travel"."Sing"]}Copy the codeSelect 1 from yuyi index
GET /yuyi/_doc/1
Copy the code3. Search criteria For obtaining user number 1
GET /yuyi/_doc/_search? Q = name: Zhu YuyiCopy the code
We find that there is a _score field in the figure above. If there are multiple data, the higher the matching degree, the higher the score
Slightly more complex query mode
GET /yuyi/_doc/_search
{
"query": {"match": {"name":"Zhu Yuyi"}}}Copy the codeReturn the same value as the image above
The return value is specified by _source
GET /yuyi/_doc/_search
{
"query": {"match": {"name":"Zhu Yuyi"}},"_source": ["name"."age"]}Copy the code
We then use nodeJS to manipulate es, where all the methods and objects are keys!
The sorting
GET /yuyi/_doc/_search
{
"query": {"match_all":{}
},
"sort":[
{
"age": {"order":"desc"}}}]Copy the codeThe match_all field is an array in which objects are passed to sort, and the above statement is to sort age, order is to sort desc descending ASC ascending.
paging
GET /yuyi/_doc/_search
{
"query": {"match_all": {}},"sort":[
{
"age": {"order":"desc"}}]."from":0."size":2
}
Copy the codeFrom indicates the number of pages to start from, and size indicates the number of pages per page
Boolean query
GET /yuyi/_doc/_search
{
"query": {"bool": {"must":[
{
"match": {"name":"Training instrument"}}, {"match": {"age":24}}]}}}Copy the codeMinimum_should_match (minimum_should_match: minimum_should_match = minimum_should_matchnamecontainsYukon instrumentfieldage 是 24The data of

Should query test
GET/yuyi _doc / _search {" query ": {" bool" : {" should ": [{" match" : {" name ":" training instrument "}}, {" match ": {" age" : 24}}]}}, "from":0, "size":2 }Copy the codeWill return as long as the name is a parent or age is 24.

Filter query
GET /yuyi/_doc/_search
{
"query": {"bool": {"must":[
{
"match": {"name":"Training instrument"}}]."filter": {"range": {"age": {"gte":10."lte":30
}
}
}
}
}
}
Copy the code
Query the filter data by using filter. Gt greater than LT less than GTE Greater than OR equal to LTE less than or equal to
Array types can also match
GET /yuyi/_doc/_search
{
"query": {"match": {"tags":"Male"}}}Copy the code
To match multiple conditions, separate them with Spaces
GET /yuyi/_doc/_search
{
"query": {"match": {"tags":"Man technique"}}}Copy the code
We found that as long as there was a match for either of these two words, it was returned, whereas the second data didn’t quite fit the keyword technology. At this time, you can judge the degree of matching by the score value in the return value.
Precise query
Term is precisely looked up directly through the inverted index
For word segmentation, term queries the exact value directly, and match uses the word segmentation to parse and query through the parsed document
The two types text keyword the text keyword is parsed by the word splitter and the keyword is not parsed by split
Test the code request by request
PUT testdb
{
"mappings": {
"properties": {
"name": {"type": "text"
},
"desc": {"type": "keyword"
}
}
}
}
PUT testdb/_doc/1
{
"name":"Parenting Readiness Sharing session"."desc":"Parenting Readiness Sharing session"
}
PUT testdb/_doc/2
{
"name":"Education ready for sharing session name"."desc":"Education is ready for sharing meeting DESC."
}
Copy the codeView word segmentation results
GET _analyze {"analyzer": "keyword", "text":" keyword"}Copy the code
GET _analyze {"analyzer": "ik_smart", "text":" Prepare to share "}Copy the code
This is the result of using the IK word divider
Precise query testing
GET /testdb/_search
{
"query": {"term": {"name":"Education"}}}Copy the codeSelect * from ‘name’ where ‘text’ is used

GET /testdb/_search
{
"query": {"term": {"desc":"Education"}}}Copy the code
At this point, we find that desc does not have a value when querying the keyword. Since we use the keyword type, we must use the keyword to prepare all the words in the sharing session to match the value. The following tests
GET /testdb/_search
{
"query": {"term": {"desc":"Parenting Readiness Sharing session"}}}Copy the code
Summary: the keyword is not parsed by the segmentation
Precise queries that match multiple values
Test code (insert multiple data)
PUT testdb/_doc/3
{
"t1":"22"."t2":"2020-09-23"
}
PUT testdb/_doc/4
{
"t1":"33"."t2":"2020-09-24"
}
Copy the codeQuery multiple values precisely using term
GET /testdb/_search
{
"query": {"bool": {"should": [{"term": {"t1":"22"}}, {"term": {"t1":"33"}}]}}}Copy the code
Highlighting the query
GET /yuyi/_search
{
"query": {"match": {"name":"Training instrument"}},"highlight": {
"fields": {
"name": {}}}}Copy the code
Highlight ‘ ‘fields’ is fixed
We don’t want to use em tags here we want to use something else
GET /yuyi/_search
{
"query": {"match": {"name":"Training instrument"}},"highlight": {
"pre_tags": "<p class='myClassName' style='color:red'>"."post_tags": "</p>"."fields": {
"name": {}}}}Copy the code
pre_tags post_tagsCustom label highlighting
Reference Documents:
The number of fragments allocated by the Elasticsearch cluster is reasonable
RESTful API interface design standards and specifications
Stop word for Elasticsearch
Elasticsearch (24) IK tokenizer configuration file and custom thesaurus
ElasticSearch 9200 and 9300 ports
Why remove Type now?
Get started with Elasticsearch
Ik_max_word and IK_smart
There are many references from other sources forgotten…