
An overview of the
Recently, I have been studying the Matrix framework and found many related blogs. I found that most of them only described the general framework process, but the details were not in-depth enough, or they were based on the earlier version, so I decided to compare the latest version with one article by myself. Students who are not familiar with Matrix Trace Canary are advised to have a look at the official document first, which is helpful for understanding this article. Without further ado, let’s begin.
Framework for parsing
Trace is based on ASM bytecode petting, which modiates the function bytecode in all class files at compile time, before and after the function is executed.
Custom MatrixTraceTransform
Transform edits the class bytecode before the class file is packaged into a dex file. Pile insertion part is not the focus of this article, there are many related articles on the Internet, do not overintroduce. Take a look at the key code
@Override
protected void onMethodEnter() {
TraceMethod traceMethod = collectedMethodMap.get(methodName);
if (traceMethod != null) {
traceMethodCount.incrementAndGet();
mv.visitLdcInsn(traceMethod.id);
mv.visitMethodInsn(INVOKESTATIC, TraceBuildConstants.MATRIX_TRACE_CLASS, "i", "(I)V", false);
}
}
Copy the codeInsert the AppMethodBeat.i() method before the execution of the function that requires the peg
@Override protected void onMethodExit(int opcode) { TraceMethod traceMethod = collectedMethodMap.get(methodName); if (traceMethod ! = null) { if (hasWindowFocusMethod && isActivityOrSubClass && isNeedTrace) { TraceMethod windowFocusChangeMethod = TraceMethod.create(-1, Opcodes.ACC_PUBLIC, className, TraceBuildConstants.MATRIX_TRACE_ON_WINDOW_FOCUS_METHOD, TraceBuildConstants.MATRIX_TRACE_ON_WINDOW_FOCUS_METHOD_ARGS); if (windowFocusChangeMethod.equals(traceMethod)) { traceWindowFocusChangeMethod(mv, className); } } traceMethodCount.incrementAndGet(); mv.visitLdcInsn(traceMethod.id); mv.visitMethodInsn(INVOKESTATIC, TraceBuildConstants.MATRIX_TRACE_CLASS, "o", "(I)V", false); }}}Copy the codeInsert the AppMethodBeat.o() method after the execution of the function that requires staking
private void traceWindowFocusChangeMethod(MethodVisitor mv, String classname) { mv.visitVarInsn(Opcodes.ALOAD, 0); mv.visitVarInsn(Opcodes.ILOAD, 1); mv.visitMethodInsn(Opcodes.INVOKESTATIC, TraceBuildConstants.MATRIX_TRACE_CLASS, "at", "(Landroid/app/Activity; Z)V", false); } private void insertWindowFocusChangeMethod(ClassVisitor cv, String classname) { MethodVisitor methodVisitor = cv.visitMethod(Opcodes.ACC_PUBLIC, TraceBuildConstants.MATRIX_TRACE_ON_WINDOW_FOCUS_METHOD, TraceBuildConstants.MATRIX_TRACE_ON_WINDOW_FOCUS_METHOD_ARGS, null, null); methodVisitor.visitCode(); methodVisitor.visitVarInsn(Opcodes.ALOAD, 0); methodVisitor.visitVarInsn(Opcodes.ILOAD, 1); methodVisitor.visitMethodInsn(Opcodes.INVOKESPECIAL, TraceBuildConstants.MATRIX_TRACE_ACTIVITY_CLASS, TraceBuildConstants.MATRIX_TRACE_ON_WINDOW_FOCUS_METHOD, TraceBuildConstants.MATRIX_TRACE_ON_WINDOW_FOCUS_METHOD_ARGS, false); traceWindowFocusChangeMethod(methodVisitor, classname); methodVisitor.visitInsn(Opcodes.RETURN); methodVisitor.visitMaxs(2, 2); methodVisitor.visitEnd(); }Copy the codeInsert the AppMethodBeat.at() method in the Activity’s onWindowFocusChanged function
TracePlugin
The start () method of the TracePlugin is the starting location of the entire project
@Override public void start() { super.start(); if (! isSupported()) { MatrixLog.w(TAG, "[start] Plugin is unSupported!" ); return; } MatrixLog.w(TAG, "start!" ); Runnable runnable = new Runnable() { @Override public void run() { if (! UIThreadMonitor.getMonitor().isInit()) { try { UIThreadMonitor.getMonitor().init(traceConfig); } catch (java.lang.RuntimeException e) { MatrixLog.e(TAG, "[start] RuntimeException:%s", e); return; } } AppMethodBeat.getInstance().onStart(); UIThreadMonitor.getMonitor().onStart(); anrTracer.onStartTrace(); frameTracer.onStartTrace(); evilMethodTracer.onStartTrace(); startupTracer.onStartTrace(); }}; if (Thread.currentThread() == Looper.getMainLooper().getThread()) { runnable.run(); } else { MatrixLog.w(TAG, "start TracePlugin in Thread[%s] but not in mainThread!" , Thread.currentThread().getId()); MatrixHandlerThread.getDefaultMainHandler().post(runnable); }}Copy the codeAppMethodBeat
The logic for hook functions is in AppMethodBeat
AppMethodBeat.i()/AppMethodBeat.o()
The previous piling function starts with I () and ends with o();
public static void i(int methodId) { if (status <= STATUS_STOPPED) { return; } if (methodId >= METHOD_ID_MAX) { //1 return; } if (status == STATUS_DEFAULT) { synchronized (statusLock) { if (status == STATUS_DEFAULT) { realExecute(); //2 status = STATUS_READY; } } } long threadId = Thread.currentThread().getId(); if (sMethodEnterListener ! = null) { sMethodEnterListener.enter(methodId, threadId); } if (threadId == sMainThreadId) { if (assertIn) { android.util.Log.e(TAG, "ERROR!!! AppMethodBeat.i Recursive calls!!!" ); return; } assertIn = true; if (sIndex < Constants.BUFFER_SIZE) { mergeData(methodId, sIndex, true); //3 } else { sIndex = 0; mergeData(methodId, sIndex, true); } ++sIndex; assertIn = false; }}Copy the codeMethodId was verified in Note 1. MethodId has the following two types
- AppMethodBeat.i(AppMethodBeat.METHOD_ID_DISPATCH); Buy a pit and explain later
- traceMethod.id = methodId.incrementAndGet(); Autoincrement of AtomicInteger during piling
The determination of the state in comment 2 is mainly based on the realExecute() method executed
private static void realExecute() {
MatrixLog.i(TAG, "[realExecute] timestamp:%s", System.currentTimeMillis());
sCurrentDiffTime = SystemClock.uptimeMillis() - sDiffTime;
sHandler.removeCallbacksAndMessages(null);
//2.1 sHandler.postDelayed(sUpdateDiffTimeRunnable, Constants.TIME_UPDATE_CYCLE_MS);
sHandler.postDelayed(checkStartExpiredRunnable = new Runnable() {
@Override
public void run() {
synchronized (statusLock) {
MatrixLog.i(TAG, "[startExpired] timestamp:%s status:%s", System.currentTimeMillis(), status);
if (status == STATUS_DEFAULT || status == STATUS_READY) {
status = STATUS_EXPIRED_START;
}
}
}
}, Constants.DEFAULT_RELEASE_BUFFER_DELAY);
//2.2 ActivityThreadHacker.hackSysHandlerCallback();
LooperMonitor.register(looperMonitorListener);
}
private static Runnable sUpdateDiffTimeRunnable = new Runnable() {
@Override
public void run() {
try {
while (true) {
while (!isPauseUpdateTime && status > STATUS_STOPPED) {
sCurrentDiffTime = SystemClock.uptimeMillis() - sDiffTime;
SystemClock.sleep(Constants.TIME_UPDATE_CYCLE_MS);
}
synchronized (updateTimeLock) {
updateTimeLock.wait();
}
}
} catch (InterruptedException e) {
MatrixLog.e(TAG, "" + e.toString());
}
}
};
Copy the codeSUpdateDiffTimeRunnable updates the sCurrentDiffTime value every 5ms by starting a thread. The official explanation is that each time the peg function obtains time increases the performance cost, after all, it is in the main thread, and the time interval below 5ms can be ignored. SBuffer, sIndex, sBuffer, sIndex, mergeData, sBuffer, sIndex
private static long[] sBuffer = new long[Constants.BUFFER_SIZE];
private static int sIndex = 0;
Copy the codeThe running records of a function are stored in sBuffer. SIndexr is the current index record of sBuffe

private static void mergeData(int methodId, int index, boolean isIn) { if (methodId == AppMethodBeat.METHOD_ID_DISPATCH) { sCurrentDiffTime = SystemClock.uptimeMillis() - sDiffTime; } long trueId = 0L; if (isIn) { trueId |= 1L << 63; } trueId |= (long) methodId << 43; trueId |= sCurrentDiffTime & 0x7FFFFFFFFFFL; sBuffer[index] = trueId; checkPileup(index); / / 3.1 sLastIndex = index; } private static void checkPileup(int index) { IndexRecord indexRecord = sIndexRecordHead; while (indexRecord ! = null) { if (indexRecord.index == index || (indexRecord.index == -1 && sLastIndex == Constants.BUFFER_SIZE - 1)) { indexRecord.isValid = false; MatrixLog.w(TAG, "[checkPileup] %s", indexRecord.toString()); sIndexRecordHead = indexRecord = indexRecord.next; } else { break; }}}Copy the codeIndexRecord is a linked list. If the condition is met, the isValid attribute of the header is set first, but the header is deleted.
AppMethodBeat.at()
Appmethodbeat.at () is also a peg function, but it monitors the Activity to start, followed by StartupTracer
OK, now that we have a rough idea of the main data formats, let’s start incorporating the code flow
EvilMethodTracer
EvilMethodTracer focuses on the API first
@Override
public void onAlive() {
super.onAlive();
if (isEvilMethodTraceEnable) {
UIThreadMonitor.getMonitor().addObserver(this);
}
}
public void addObserver(LooperObserver observer) {
if (!isAlive) {
onStart();
}
synchronized (observers) {
observers.add(observer);
}
}
Copy the codeSo I’m setting a listener here, and you can see that I’m actually setting a listener in LooperObserver, and I’m following up to see when the implementation function in EvilMethodTracer calls back, Find dispatch(x.char (0) == ‘>’, x) in LooperPrinter; methods
class LooperPrinter implements Printer { public Printer origin; boolean isHasChecked = false; boolean isValid = false; LooperPrinter(Printer printer) { this.origin = printer; } @Override public void println(String x) { if (null ! = origin) { origin.println(x); if (origin == this) { throw new RuntimeException(TAG + " origin == this"); } } if (! isHasChecked) { isValid = x.charAt(0) == '>' || x.charAt(0) == '<'; isHasChecked = true; if (! isValid) { MatrixLog.e(TAG, "[println] Printer is inValid! x:%s", x); } } if (isValid) { dispatch(x.charAt(0) == '>', x); / /}}}Copy the codeResetPrinter () called when LooperMonitor is initialized
private synchronized void resetPrinter() { Printer originPrinter = null; try { if (! isReflectLoggingError) { originPrinter = ReflectUtils.get(looper.getClass(), "mLogging", looper); if (originPrinter == printer && null ! = printer) { return; } } } catch (Exception e) { isReflectLoggingError = true; Log.e(TAG, "[resetPrinter] %s", e); } if (null ! = printer) { MatrixLog.w(TAG, "maybe thread:%s printer[%s] was replace other[%s]!" , looper.getThread().getName(), printer, originPrinter); } looper.setMessageLogging(printer = new LooperPrinter(originPrinter)); if (null ! = originPrinter) { MatrixLog.i(TAG, "reset printer, originPrinter[%s] in %s", originPrinter, looper.getThread().getName()); }}Copy the codeAs you can see, this method gets the mLogging property in Looper by reflection. Let’s look at the code in Looper
for (;;) { Message msg = queue.next(); // might block final Printer logging = me.mLogging; if (logging ! = null) { logging.println(">>>>> Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what); }... // Omit irrelevant code if (logging! = null) { logging.println("<<<<< Finished to " + msg.target + " " + msg.callback); }}Copy the codeIt can be found that Looper prints logs when processing the beginning and end of a message. Based on this, LooperMonitor implements whether the main thread timeout occurs when processing a message.
Back to EvilMethodTracer and UIThreadMonitor, their dispatchBegin () is called when a message from the main thread starts dispatch and their dispatchEnd () is called when dispatch ends.
In the UIThreadMonitor
private void dispatchBegin() { token = dispatchTimeMs[0] = SystemClock.uptimeMillis(); dispatchTimeMs[2] = SystemClock.currentThreadTimeMillis(); AppMethodBeat.i(AppMethodBeat.METHOD_ID_DISPATCH); //1 synchronized (observers) { for (LooperObserver observer : observers) { if (! observer.isDispatchBegin()) { observer.dispatchBegin(dispatchTimeMs[0], dispatchTimeMs[2], token); }}}}Copy the codeMethodbeat.METHOD_ID_DISPATCH is used to start and end the main thread’s message. methodbeat. The dispatchEnd () method is similar and will not be introduced
@Override public void dispatchBegin(long beginMs, long cpuBeginMs, long token) { super.dispatchBegin(beginMs, cpuBeginMs, token); indexRecord = AppMethodBeat.getInstance().maskIndex("EvilMethodTracer#dispatchBegin"); } public IndexRecord maskIndex(String source) { if (sIndexRecordHead == null) {//1 sIndexRecordHead = new IndexRecord(sIndex - 1); sIndexRecordHead.source = source; return sIndexRecordHead; } else { IndexRecord indexRecord = new IndexRecord(sIndex - 1); indexRecord.source = source; IndexRecord record = sIndexRecordHead; IndexRecord last = null; while (record ! = null) { if (indexRecord.index <= record.index) { if (null == last) { IndexRecord tmp = sIndexRecordHead; sIndexRecordHead = indexRecord; indexRecord.next = tmp; } else { IndexRecord tmp = last.next; if (null ! = last.next) { last.next = indexRecord; } indexRecord.next = tmp; } return indexRecord; //2 } last = record; record = record.next; } last.next = indexRecord; return indexRecord; / / 3}}Copy the codeThe maskIndex method is used to generate an IndexRecord node, which is the operation of adding nodes to a single linked list. The index property of the IndexRecord is determined by the index of the current sBuffer, sIndex, which is equivalent to the index of the peg method in the sBuffer.
- Set to the head node directly at comment 1
- At comment 2, if last==null is inserted before the current sIndexRecordHead, last! =null is inserted in the middle of the sIndexRecordHead, depending on the index size of the node
- Note 3 is added directly to the last node
So if we go back to the Illegitimate MethodTracer where we just said dispatchBegin, we’re definitely going to say dispatchEnd, which is the main subclass as dispatchBegin
@Override public void dispatchEnd(long beginMs, long cpuBeginMs, long endMs, long cpuEndMs, long token, boolean isBelongFrame) { super.dispatchEnd(beginMs, cpuBeginMs, endMs, cpuEndMs, token, isBelongFrame); long start = config.isDevEnv() ? System.currentTimeMillis() : 0; try { long dispatchCost = endMs - beginMs; if (dispatchCost >= evilThresholdMs) { long[] data = AppMethodBeat.getInstance().copyData(indexRecord); long[] queueCosts = new long[3]; System.arraycopy(queueTypeCosts, 0, queueCosts, 0, 3); String scene = AppMethodBeat.getVisibleScene(); MatrixHandlerThread.getDefaultHandler().post(new AnalyseTask(isForeground(), scene, data, queueCosts, cpuEndMs - cpuBeginMs, endMs - beginMs, endMs)); } } finally { indexRecord.release(); if (config.isDevEnv()) { String usage = Utils.calculateCpuUsage(cpuEndMs - cpuBeginMs, endMs - beginMs); MatrixLog.v(TAG, "[dispatchEnd] token:%s cost:%sms cpu:%sms usage:%s innerCost:%s", token, endMs - beginMs, cpuEndMs - cpuBeginMs, usage, System.currentTimeMillis() - start); }}}Copy the codeWhen dispatchCost exceeds the threshold is a time consuming method, long [] data = AppMethodBeat. GetInstance (). CopyData (indexRecord); Get a record of time-consuming methods in sBuffer
public long[] copyData(IndexRecord startRecord) { return copyData(startRecord, new IndexRecord(sIndex - 1)); } private long[] copyData(IndexRecord startRecord, IndexRecord endRecord) { long current = System.currentTimeMillis(); long[] data = new long[0]; try { if (startRecord.isValid && endRecord.isValid) { int length; int start = Math.max(0, startRecord.index); int end = Math.max(0, endRecord.index); if (end > start) { length = end - start + 1; data = new long[length]; System.arraycopy(sBuffer, start, data, 0, length); } else if (end < start) { length = 1 + end + (sBuffer.length - start); data = new long[length]; System.arraycopy(sBuffer, start, data, 0, sBuffer.length - start); System.arraycopy(sBuffer, 0, data, sBuffer.length - start, end + 1); } return data; } return data; } catch (OutOfMemoryError e) { MatrixLog.e(TAG, e.toString()); return data; } finally { MatrixLog.i(TAG, "[copyData] [%s:%s] length:%s cost:%sms", Math.max(0, startRecord.index), endRecord.index, data.length, System.currentTimeMillis() - current); }}Copy the codeStartRecord is the IndexRecord node generated in dispatchBegin. Index in endRecord corresponds to the current index in sBuffer. This captures all the functions that a message executes during dispatch.
Since the default length of the sBuffer array is 1000000, sIndex will be set to 0 when the maximum value is reached, so end< start occurs, as shown in the following code
if (sIndex < Constants.BUFFER_SIZE) {
mergeData(methodId, sIndex, true);
} else {
sIndex = 0;
mergeData(methodId, sIndex, true);
}
Copy the codeGo back to the dispatchEnd () method
String scene = AppMethodBeat.getVisibleScene(); Scene is actually the current activity
private void updateScene(Activity activity) {
visibleScene = activity.getClass().getName();
}
Copy the codeFinally, analyze and report data in analyse Task ()
TraceDataUtils.structuredDataToStack(data, stack, true, endMs); public static void structuredDataToStack(long[] buffer, LinkedList<MethodItem> result, boolean isStrict, long endTime) { long lastInId = 0L; int depth = 0; LinkedList<Long> rawData = new LinkedList<>(); boolean isBegin = ! isStrict; for (long trueId : buffer) {// 1 if (0 == trueId) { continue; } if (isStrict) { if (isIn(trueId) && AppMethodBeat.METHOD_ID_DISPATCH == getMethodId(trueId)) { isBegin = true; } if (! isBegin) { MatrixLog.d(TAG, "never begin! pass this method[%s]", getMethodId(trueId)); continue; } } if (isIn(trueId)) { lastInId = getMethodId(trueId); if (lastInId == AppMethodBeat.METHOD_ID_DISPATCH) { depth = 0; } depth++; rawData.push(trueId); } else { int outMethodId = getMethodId(trueId); if (! rawData.isEmpty()) { long in = rawData.pop(); depth--; int inMethodId; LinkedList<Long> tmp = new LinkedList<>(); tmp.add(in); while ((inMethodId = getMethodId(in)) ! = outMethodId && ! rawData.isEmpty()) { MatrixLog.w(TAG, "pop inMethodId[%s] to continue match ouMethodId[%s]", inMethodId, outMethodId); in = rawData.pop(); depth--; tmp.add(in); } if (inMethodId ! = outMethodId && inMethodId == AppMethodBeat.METHOD_ID_DISPATCH) { MatrixLog.e(TAG, "inMethodId[%s] ! = outMethodId[%s] throw this outMethodId!" , inMethodId, outMethodId); rawData.addAll(tmp); depth += rawData.size(); continue; } long outTime = getTime(trueId); long inTime = getTime(in); long during = outTime - inTime; if (during < 0) { MatrixLog.e(TAG, "[structuredDataToStack] trace during invalid:%d", during); rawData.clear(); result.clear(); return; } MethodItem methodItem = new MethodItem(outMethodId, (int) during, depth); addMethodItem(result, methodItem); //2 } else { MatrixLog.w(TAG, "[structuredDataToStack] method[%s] not found in! ", outMethodId); } } } while (! rawData.isEmpty() && isStrict) {//3 long trueId = rawData.pop(); int methodId = getMethodId(trueId); boolean isIn = isIn(trueId); long inTime = getTime(trueId) + AppMethodBeat.getDiffTime(); MatrixLog.w(TAG, "[structuredDataToStack] has never out method[%s], isIn:%s, inTime:%s, endTime:%s,rawData size:%s", methodId, isIn, inTime, endTime, rawData.size()); if (! isIn) { MatrixLog.e(TAG, "[structuredDataToStack] why has out Method[%s]? is wrong! ", methodId); continue; } MethodItem methodItem = new MethodItem(methodId, (int) (endTime - inTime), rawData.size()); addMethodItem(result, methodItem); } TreeNode root = new TreeNode(null, null); stackToTree(result, root); //4 result.clear(); treeToStack(root, result); / / 5}Copy the codeLet’s start with the array traversal in comment 1. The main thing here is to convert the methods recorded in the array to a list of MethodItems with a hierarchical attribute depth
Fun1 () {//depth=0 fun2 () {//depth=1 fun3 () {//depth= 2} fun4 () {//depth= 2}}}Copy the codeMethodItemd also has fairly simple properties depth, time, method ID
public MethodItem(int methodId, int durTime, int depth) {
this.methodId = methodId;
this.durTime = durTime;
this.depth = depth;
}
Copy the codeComment 2 adds the generated methodItem to the head of the list and updates it if there is the same methodId node below
private static int addMethodItem(LinkedList<MethodItem> resultStack, MethodItem item) { if (AppMethodBeat.isDev) { Log.v(TAG, "method:" + item); } MethodItem last = null; if (! resultStack.isEmpty()) { last = resultStack.peek(); } if (null ! = last && last.methodId == item.methodId && last.depth == item.depth && 0 ! = item.depth) { item.durTime = item.durTime == Constants.DEFAULT_ANR ? last.durTime : item.durTime; last.mergeMore(item.durTime); return last.durTime; } else { resultStack.push(item); return item.durTime; }}Copy the codeNote 3 is mainly about the verification operation of abnormal data. Generally, the intercepted sBuffer data I and O functions are one-to-one corresponding.
Note 4 is to transform the linked list data into a tree structure. Note that this is not a binary tree. It can be understood as a multi-level tree data format of provinces and cities
public static final class TreeNode {
MethodItem item;
TreeNode father;
LinkedList<TreeNode> children = new LinkedList<>();
TreeNode(MethodItem item, TreeNode father) {
this.item = item;
this.father = father;
}
private int depth() {
return null == item ? 0 : item.depth;
}
private void add(TreeNode node) {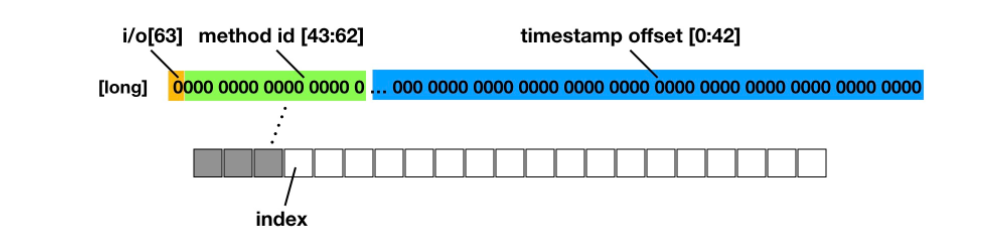
children.addFirst(node);
}
private boolean isLeaf() {
return children.isEmpty();
}
}
Copy the code
Back to AnalyseTask’s analyse ()
TraceDataUtils.trimStack(stack, Constants.TARGET_EVIL_METHOD_STACK, new TraceDataUtils.IStructuredDataFilter() { @Override public boolean isFilter(long during, int filterCount) { return during < filterCount * Constants.TIME_UPDATE_CYCLE_MS; } @Override public int getFilterMaxCount() { return Constants.FILTER_STACK_MAX_COUNT; } @Override public void fallback(List<MethodItem> stack, int size) { MatrixLog.w(TAG, "[fallback] size:%s targetSize:%s stack:%s", size, Constants.TARGET_EVIL_METHOD_STACK, stack); Iterator iterator = stack.listIterator(Math.min(size, Constants.TARGET_EVIL_METHOD_STACK)); while (iterator.hasNext()) { iterator.next(); iterator.remove(); }}});Copy the codeThe focus here is on filtering the collected data
public static void trimStack(List<MethodItem> stack, int targetCount, IStructuredDataFilter filter) { if (0 > targetCount) { stack.clear(); return; } int filterCount = 1; int curStackSize = stack.size(); while (curStackSize > targetCount) {//1 ListIterator<MethodItem> iterator = stack.listIterator(stack.size()); while (iterator.hasPrevious()) { MethodItem item = iterator.previous(); if (filter.isFilter(item.durTime, filterCount)) {//2 iterator.remove(); curStackSize--; if (curStackSize <= targetCount) { return; } } } curStackSize = stack.size(); filterCount++; if (filter.getFilterMaxCount() < filterCount) { break; } } int size = stack.size(); if (size > targetCount) { filter.fallback(stack, size); }}Copy the codeNote 1 sets the threshold value of more than 30 nodes before filtering. Note 2 judges whether filtering is needed for specific time consumption.
Continue to the analyse ()
long stackCost = Math.max(cost, TraceDataUtils.stackToString(stack, reportBuilder, logcatBuilder));
Copy the codeHere to obtain the maximum time, the logic is relatively simple
String stackKey = TraceDataUtils.getTreeKey(stack, stackCost);
Copy the codeHere is a key value required to obtain the time consuming method detection data report. See for details
public static String getTreeKey(List<MethodItem> stack, long stackCost) {
StringBuilder ss = new StringBuilder();
long allLimit = (long) (stackCost * Constants.FILTER_STACK_KEY_ALL_PERCENT);
LinkedList<MethodItem> sortList = new LinkedList<>();
for (MethodItem item : stack) {
if (item.durTime >= allLimit) {
sortList.add(item);
}
}
Collections.sort(sortList, new Comparator<MethodItem>() {
@Override
public int compare(MethodItem o1, MethodItem o2) {
return Integer.compare((o2.depth + 1) * o2.durTime, (o1.depth + 1) * o1.durTime);
}
});
if (sortList.isEmpty() && !stack.isEmpty()) {
MethodItem root = stack.get(0);
sortList.add(root);
} else if (sortList.size() > 1 && sortList.peek().methodId == AppMethodBeat.METHOD_ID_DISPATCH) {
sortList.removeFirst();
}
for (MethodItem item : sortList) {
ss.append(item.methodId + "|");
break;
}
return ss.toString();
}
Copy the codeThe logic is not complicated. The data is filtered by durTime first, and then sorted by depth and durTime. Depth is needed because of the call stack hierarchy, not just the time of a single method.
The analyse is followed by the setting and reporting of json data.
So much for EvilMethodTracer logic.
AnrTracer
It’s easy to understand the logic associated with EvilMethodTracer, AnrTracer, because the root cause of ANR is program unresponsiveness due to main thread time
@Override public void dispatchBegin(long beginMs, long cpuBeginMs, long token) { super.dispatchBegin(beginMs, cpuBeginMs, token); anrTask = new AnrHandleTask(AppMethodBeat.getInstance().maskIndex("AnrTracer#dispatchBegin"), token); if (traceConfig.isDevEnv()) { MatrixLog.v(TAG, "* [dispatchBegin] token:%s index:%s", token, anrTask.beginRecord.index); } anrHandler.postDelayed(anrTask, Constants.DEFAULT_ANR - (SystemClock.uptimeMillis() - token)); } @Override public void dispatchEnd(long beginMs, long cpuBeginMs, long endMs, long cpuEndMs, long token, boolean isBelongFrame) { super.dispatchEnd(beginMs, cpuBeginMs, endMs, cpuEndMs, token, isBelongFrame); if (traceConfig.isDevEnv()) { MatrixLog.v(TAG, "[dispatchEnd] token:%s cost:%sms cpu:%sms usage:%s", token, endMs - beginMs, cpuEndMs - cpuBeginMs, Utils.calculateCpuUsage(cpuEndMs - cpuBeginMs, endMs - beginMs)); } if (null ! = anrTask) { anrTask.getBeginRecord().release(); anrHandler.removeCallbacks(anrTask); }}Copy the code- DispatchBegin delays the sending of a message
- DispatchEnd cancels the delayed message. If it does not cancel, ANR has occurred
- An ANR report occurred. Procedure
StartupTracer
@Override protected void onAlive() { super.onAlive(); MatrixLog.i(TAG, "[onAlive] isStartupEnable:%s", isStartupEnable); if (isStartupEnable) { AppMethodBeat.getInstance().addListener(this); Matrix.with().getApplication().registerActivityLifecycleCallbacks(this); }}Copy the codeThere are two listeners registered here
- IAppMethodBeatListener
- ActivityLifecycleCallbacks global listening Activity life cycle
Look at IAppMethodBeatListener and see that his onActivityFocused () method is called from at () in AppMethodBeat, which was inserted at compile time just like the I () o () methods. The insertion location is in the onWindowFocusChange method of the Activity subclass
public static void at(Activity activity, boolean isFocus) {
String activityName = activity.getClass().getName();
if (isFocus) {
if (sFocusActivitySet.add(activityName)) {
synchronized (listeners) {
for (IAppMethodBeatListener listener : listeners) {
listener.onActivityFocused(activityName);
}
}
MatrixLog.i(TAG, "[at] visibleScene[%s] has %s focus!", getVisibleScene(), "attach");
}
} else {
if (sFocusActivitySet.remove(activityName)) {
MatrixLog.i(TAG, "[at] visibleScene[%s] has %s focus!", getVisibleScene(), "detach");
}
}
}
Copy the codeThe main callbacks in StartupTracer have been identified, so let’s look at them
@Override public void onActivityFocused(String activity) { if (isColdStartup()) { if (firstScreenCost == 0) { this.firstScreenCost = uptimeMillis() - ActivityThreadHacker.getEggBrokenTime(); } if (hasShowSplashActivity) { coldCost = uptimeMillis() - ActivityThreadHacker.getEggBrokenTime(); } else { if (splashActivities.contains(activity)) { hasShowSplashActivity = true; } else if (splashActivities.isEmpty()) { MatrixLog.i(TAG, "default splash activity[%s]", activity); coldCost = firstScreenCost; } else { MatrixLog.w(TAG, "pass this activity[%s] at duration of start up! splashActivities=%s", activity, splashActivities); } } if (coldCost > 0) { analyse(ActivityThreadHacker.getApplicationCost(), firstScreenCost, coldCost, false); } } else if (isWarmStartUp()) { isWarmStartUp = false; long warmCost = uptimeMillis() - ActivityThreadHacker.getLastLaunchActivityTime(); if (warmCost > 0) { analyse(ActivityThreadHacker.getApplicationCost(), firstScreenCost, warmCost, true); }}}Copy the codeThe logic here is not complicated mainly because of the meaning of some variables
- ActivityThreadHacker.getEggBrokenTime(); The first time appMethodBeat.i () is called is the time the program starts
- ActivityThreadHacker.getLastLaunchActivityTime(); Here we listen for msG.what == LAUNCH_ACTIVITY messages by reflecting the mH Handler in the ActivityThread.
The next analyse () method is data analysis and report logic similar to EvilMethodTracer before
private void analyse(long applicationCost, long firstScreenCost, long allCost, boolean isWarmStartUp) { MatrixLog.i(TAG, "[report] applicationCost:%s firstScreenCost:%s allCost:%s isWarmStartUp:%s", applicationCost, firstScreenCost, allCost, isWarmStartUp); long[] data = new long[0]; if (! isWarmStartUp && allCost >= coldStartupThresholdMs) { // for cold startup data = AppMethodBeat.getInstance().copyData(ActivityThreadHacker.sApplicationCreateBeginMethodIndex); ActivityThreadHacker.sApplicationCreateBeginMethodIndex.release(); } else if (isWarmStartUp && allCost >= warmStartupThresholdMs) { data = AppMethodBeat.getInstance().copyData(ActivityThreadHacker.sLastLaunchActivityMethodIndex); ActivityThreadHacker.sLastLaunchActivityMethodIndex.release(); } MatrixHandlerThread.getDefaultHandler().post(new AnalyseTask(data, applicationCost, firstScreenCost, allCost, isWarmStartUp, ActivityThreadHacker.sApplicationCreateScene)); }Copy the codeFrameTracer
The FrameTracer module mainly FPSCollector and FrameDecorator. The main principle is to get VSync VSync related callbacks through Choreographer.
choreographer = Choreographer.getInstance();
callbackQueueLock = reflectObject(choreographer, "mLock");
callbackQueues = reflectObject(choreographer, "mCallbackQueues");
addInputQueue = reflectChoreographerMethod(callbackQueues[CALLBACK_INPUT], ADD_CALLBACK, long.class, Object.class, Object.class);
addAnimationQueue = reflectChoreographerMethod(callbackQueues[CALLBACK_ANIMATION], ADD_CALLBACK, long.class, Object.class, Object.class);
addTraversalQueue = reflectChoreographerMethod(callbackQueues[CALLBACK_TRAVERSAL], ADD_CALLBACK, long.class, Object.class, Object.class);
frameIntervalNanos = reflectObject(choreographer, "mFrameIntervalNanos");
Copy the codeGet Choreographer related instances through reflection
private synchronized void addFrameCallback(int type, Runnable callback, boolean isAddHeader) { if (callbackExist[type]) { MatrixLog.w(TAG, "[addFrameCallback] this type %s callback has exist! isAddHeader:%s", type, isAddHeader); return; } if (! isAlive && type == CALLBACK_INPUT) { MatrixLog.w(TAG, "[addFrameCallback] UIThreadMonitor is not alive!" ); return; } try { synchronized (callbackQueueLock) { Method method = null; switch (type) { case CALLBACK_INPUT: method = addInputQueue; break; case CALLBACK_ANIMATION: method = addAnimationQueue; break; case CALLBACK_TRAVERSAL: method = addTraversalQueue; break; } if (null ! = method) {//1 method.invoke(callbackQueues[type], ! isAddHeader ? SystemClock.uptimeMillis() : -1, callback, null); callbackExist[type] = true; } } } catch (Exception e) { MatrixLog.e(TAG, e.toString()); }}Copy the codeNote 1: Add data to mCallbackQueues in Choreographer, the result of which is returned in callback and time consuming data is set
public void addCallbackLocked(long dueTime, Object action, Object token) { CallbackRecord callback = obtainCallbackLocked(dueTime, action, token); CallbackRecord entry = mHead; if (entry == null) { mHead = callback; return; } if (dueTime < entry.dueTime) { callback.next = entry; mHead = callback; return; } while (entry.next ! = null) { if (dueTime < entry.next.dueTime) { callback.next = entry.next; break; } entry = entry.next; } entry.next = callback; }Copy the codeprivate void doQueueBegin(int type) { queueStatus[type] = DO_QUEUE_BEGIN; queueCost[type] = System.nanoTime(); } private void doQueueEnd(int type) { queueStatus[type] = DO_QUEUE_END; queueCost[type] = System.nanoTime() - queueCost[type]; synchronized (this) { callbackExist[type] = false; }}Copy the codeThis is where the callback sets the data, but queueCost doesn’t use it. Emmm actually choretracer does not use FrameTracer, it still uses the main thread message distribution logic, the same logic as EvilMethodTracer
The core code in FrameTracer is as follows
private void notifyListener(final String visibleScene, final long taskCostMs, final long frameCostMs, final boolean isContainsFrame) {
long start = System.currentTimeMillis();
try {
synchronized (listeners) {
for (final IDoFrameListener listener : listeners) {
if (config.isDevEnv()) {
listener.time = SystemClock.uptimeMillis();
}
final int dropFrame = (int) (taskCostMs / frameIntervalMs);
listener.doFrameSync(visibleScene, taskCostMs, frameCostMs, dropFrame, isContainsFrame);
if (null != listener.getExecutor()) {
listener.getExecutor().execute(new Runnable() {
@Override
public void run() {
listener.doFrameAsync(visibleScene, taskCostMs, frameCostMs, dropFrame, isContainsFrame);//1
}
});
}
}
}
} finally {
long cost = System.currentTimeMillis() - start;
if (config.isDebug() && cost > frameIntervalMs) {
MatrixLog.w(TAG, "[notifyListener] warm! maybe do heavy work in doFrameSync! size:%s cost:%sms", listeners.size(), cost);
}
}
}
Copy the codeNote 1 has specific implementations in FPSCollector and FrameDecorator
Processing and reporting of frame drop data in FPSCollector
void collect(int droppedFrames, boolean isContainsFrame) {
long frameIntervalCost = UIThreadMonitor.getMonitor().getFrameIntervalNanos();
sumFrameCost += (droppedFrames + 1) * frameIntervalCost / Constants.TIME_MILLIS_TO_NANO;
sumDroppedFrames += droppedFrames;
sumFrame++;
if (!isContainsFrame) {
sumTaskFrame++;
}
if (droppedFrames >= frozenThreshold) {
dropLevel[DropStatus.DROPPED_FROZEN.index]++;
dropSum[DropStatus.DROPPED_FROZEN.index] += droppedFrames;
} else if (droppedFrames >= highThreshold) {
dropLevel[DropStatus.DROPPED_HIGH.index]++;
dropSum[DropStatus.DROPPED_HIGH.index] += droppedFrames;
} else if (droppedFrames >= middleThreshold) {
dropLevel[DropStatus.DROPPED_MIDDLE.index]++;
dropSum[DropStatus.DROPPED_MIDDLE.index] += droppedFrames;
} else if (droppedFrames >= normalThreshold) {
dropLevel[DropStatus.DROPPED_NORMAL.index]++;
dropSum[DropStatus.DROPPED_NORMAL.index] += droppedFrames;
} else {
dropLevel[DropStatus.DROPPED_BEST.index]++;
dropSum[DropStatus.DROPPED_BEST.index] += (droppedFrames < 0 ? 0 : droppedFrames);
}
}
Copy the code- The number of frames collected is calculated by the time the main line becomes a dispatch
- The number of frames dropped is set to 5 levels
FrameDecorator creates a view based on the frame rate. This part of the logic is relatively simple, do not go into too much.
@Override public void doFrameAsync(String visibleScene, long taskCost, long frameCostMs, int droppedFrames, boolean isContainsFrame) { super.doFrameAsync(visibleScene, taskCost, frameCostMs, droppedFrames, isContainsFrame); sumFrameCost += (droppedFrames + 1) * UIThreadMonitor.getMonitor().getFrameIntervalNanos() / Constants.TIME_MILLIS_TO_NANO; sumFrames += 1; long duration = sumFrameCost - lastCost[0]; long collectFrame = sumFrames - lastFrames[0]; if (duration >= 200) { final float fps = Math.min(60.f, 1000.f * collectFrame / duration); updateView(view.fpsView, fps); view.chartView.addFps((int) fps); lastCost[0] = sumFrameCost; lastFrames[0] = sumFrames; mainHandler.removeCallbacks(updateDefaultRunnable); mainHandler.postDelayed(updateDefaultRunnable, 130); } } private void updateView(final TextView view, final float fps) { mainHandler.post(new Runnable() { @Override public void run() { view.setText(String.format("%.2f FPS", fps)); if (fps >= 50) { view.setTextColor(view.getResources().getColor(android.R.color.holo_green_dark)); } else if (fps >= 30) { view.setTextColor(view.getResources().getColor(android.R.color.holo_orange_dark)); } else { view.setTextColor(view.getResources().getColor(android.R.color.holo_red_dark)); }}}); }Copy the codeconclusion
After introducing the framework of Matrix Trace — Canary, the framework structure is relatively clear and not complicated, mainly due to the complicated data processing module. However, this is also one of the advantages of Trace compared with other frameworks, which can completely record the time-consuming function call stack.